This project was creating a predictor that could take any property in the U.S. and make a prediction on its probable income from being used as short-term rental (like airbnb or vrbo) or as a long-term lease rental. The predictions were be based primarily on the location of the property, and the features of the building.
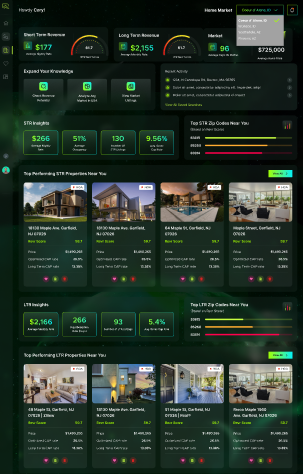
The project began as a proof-of-concept using a latitude/longtitude grid over the Coeur d’Alene area to determine if an ML model could perform any better than random chance in predicing per-bedroom revenues. Once that was established, it expanded to use more data by extracting text values from the property descriptions about features of the house and the local attractions in the surrounding area, and the dataset was expanded to cover samplings of houses from all over the US. Other kinds of data were also added into provide more context such as distance and rates of nearest hotels.
For feature selection, outlier detection, and sanity checks on the AI output, we developed regression curves based on number of rooms, square footage, lot size, price-to-revenue. Many property-attributes were sparse requiring aggregating them into larger categories.
Some challenges in the project were shifting data sources that included different kinds/levels of information detail (humans are very inconsistent in what they include in descriptive text), differing quantity and reliability of past performance data, varying levels of location precision, and mixed-use properties that were used for hort-term rentals during peak season and per-month leases off season.
To develop the area averages, I used several approaches. The first was recursive approach that sub-divided blocks of longitude/latitude as long as they contained enough data points. In very rural areas, those blocks might be 1/10 of a degree across. In downtown urban areas, the areas could be a small as a few hundred yards across. The second and third approaches were simpler aggregations by zipcode and town (though city/town names required standardization for since the entries didn’t always match to the official US city dbs because of neighborhood/burough names, abbreviations, nicknames, etc)